Last updated May 7, 2026
Generative AI vs Machine Learning: Differences and Use Cases

10 mins read
Summarize with AI:



You're three sprints into planning a new AI feature. One engineer wants to train a classification model on your historical data. Another is pushing for a GPT-based assistant. Your product manager is nodding at both. Nobody's wrong, exactly, but nobody's solving the same problem either.
This is where the generative ai vs machine learning debate gets expensive fast. Teams confuse the two when scoping features, allocating budgets, and designing data pipelines, and that confusion tends to surface at the worst possible moment: after the architecture is already built.
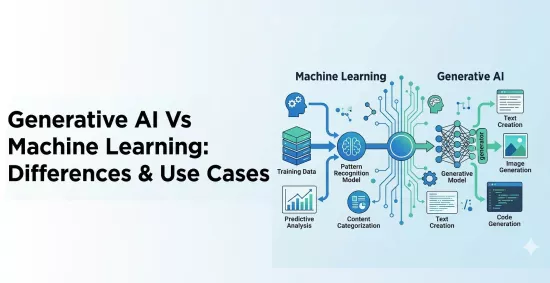
The difference between generative AI and machine learning isn't subtle. Machine learning takes historical data and produces predictions. Generative AI produces new content, text, code, images, audio, that didn't exist before. One optimizes a decision. The other creates an output.
Both matter. Both have a place. But machine learning vs generative AI is a real choice with real cost implications.
This post walks through a quick side-by-side comparison, how each approach actually works under the hood, the key tradeoffs in data and infrastructure, where each one belongs in a real product, and a practical framework for deciding which to use or whether you need both.
Machine learning predicts outcomes from data, while generative AI creates new content based on learned patterns.
| Dimension | Machine Learning | Generative AI |
|---|---|---|
| Goal | Predict, classify, or rank | Generate new content |
| Output | Score, label, or decision | Text, image, code, audio |
| Typical data | Structured, labeled datasets | Unstructured, unlabeled corpora |
| Training style | Supervised or task-specific | Self-supervised on foundation models |
| Cost | Lower compute, cheaper inference | High compute, expensive at scale |
| Latency | Fast, predictable | Slower, variable |
| Explainability | Generally higher | Low to moderate |
| Evaluation | Accuracy, F1, AUC | Human judgment, BLEU, perplexity |
| Risk profile | Bias in predictions | Hallucination, misuse, IP exposure |
| Common model families | Regression, tree-based, recommenders | Transformers, GANs, diffusion models |
Generative AI is a subset of machine learning, not a separate field. It sits within the deep learning branch of ML, which itself falls under the broader AI umbrella. Every generative model is an ML model, but the reverse is not true.
Where traditional ML relies on regression, gradient-boosted trees, and collaborative filtering to return a bounded answer, generative models like transformers, GANs, and diffusion models produce open-ended outputs. A random forest tells you whether a loan will default. GPT-4 writes the rejection letter. A diffusion model designs the marketing banner. Same parent discipline, completely different mechanics and output contracts.
That distinction matters when you scope a project. Picking a transformer for a fraud classification task is overkill by an order of magnitude. Expecting a gradient-boosted classifier to draft customer communications is simply impossible, no amount of tuning changes what a model architecture can do.
Getting this wrong is not an academic problem. The difference between generative AI and machine learning has direct consequences on your delivery timeline, your AWS bill, your compliance posture, and whether your team ships a working product or spends four months building something that fundamentally cannot do the job.
A classification model that detects fraudulent transactions runs inference in milliseconds and costs fractions of a cent per call. An LLM processing the same decision through token-based inference can run 10x to 100x higher in per-query cost, with latency jumping from under 50ms to several seconds depending on context window size and provider (source: Anyscale inference benchmarks, 2023). That gap is not a rounding error. At production volume, it reshapes your entire cloud spend.
The reverse problem is just as expensive. If you need a document assistant that drafts responses or interprets open-ended user queries, a classification model cannot do that regardless of how well you train it. You will hit a structural ceiling, not a tuning problem.
Generative AI projects also carry compliance exposure that traditional ML workflows do not. When your model generates free-form text or synthesizes content, your legal team needs to audit outputs for hallucination risk, data privacy, and regulated-industry restrictions. That work takes time and requires clear ownership from the start.
Traditional ML lives on structured, labeled data. Your pipeline depends on clean historical records, consistent feature engineering, and enough labeled examples to train a reliable model. The quality of your annotations directly determines production accuracy.
Generative AI flips that entirely. Most product teams never train from scratch. Instead, they adapt foundation models through fine-tuning or retrieval-augmented generation, which shifts your data work toward curating domain-specific context, building vector indexes, and managing retrieval quality. Your success metric is no longer model accuracy on a held-out test set. You are measuring response relevance, output consistency, and failure rate on adversarial inputs.
Both paths require serious data investment. The shape of that investment is completely different, and conflating them at the architecture stage produces pipelines that cannot serve either use case well when you hit production load.
The mechanics behind each approach are genuinely different, not just in degree but in kind. Understanding how machine learning works versus how generative AI works changes how you scope projects, evaluate vendors, and catch bad technical advice early.
Take a classic example: predicting customer churn for a SaaS product.
Your team pulls 18 months of structured, tabular data — subscription tier, login frequency, support ticket volume, days since last active session, payment history. Each row gets a label: churned or retained. That labeled dataset gets split into a training set (roughly 80%) and a validation set (the remaining 20% the model never sees during training).
A classification model trains on the training split, adjusting its internal parameters to minimize prediction error against those known labels. After training, you run it against the validation set and measure performance using AUC or precision-recall curves, both of which tell you more than raw accuracy when your churn class is imbalanced.
Once the model clears your threshold on validation data, it ships to production. From that point on, it takes a new customer record as input and returns a churn probability score. That's the entire output. One number, within a bounded range, for one specific question.
Nothing is generated. Nothing is invented. The model found statistical patterns in historical behavior and learned to apply them to new inputs. Fast, cheap, and predictable when the problem fits the format.
Generative AI starts from a fundamentally different place. Large language models train on massive unstructured corpora using self-supervised learning objectives, meaning the training signal comes from the data itself, not from human-assigned labels. The core task during pre-training is next-token prediction: given the tokens that came before, what token is most likely next?
Through billions of those predictions across trillions of tokens, the model develops embeddings, dense numerical representations of words, concepts, and relationships. The transformer architecture lets the model attend to all relevant tokens within its context window simultaneously, which is why it can handle complex dependencies across long passages rather than just the last few words.
When you send a prompt, the model runs inference: it processes your input against everything it learned during training and samples from a probability distribution over its vocabulary to produce each token in sequence. That sampling process is why outputs feel fluent and coherent. It's also why they can be completely wrong.
Here's a direct example. You prompt: "Summarize the key risks in our Q3 vendor contract." The model produces a polished, well-structured paragraph. But if the contract contains unusual indemnification language the model has never seen patterned that way, it may generate a summary that sounds authoritative and misses the actual risk entirely.
That's not a bug to be patched. Next-token prediction optimizes for plausibility, not truth. Diffusion models follow a different path for images and audio, but the same principle holds: generation quality and factual accuracy are separate problems.
The architecture produces remarkable outputs. You should still verify every one that matters.
The comparison between generative AI vs machine learning breaks down cleanly across five dimensions. Each one carries real architectural consequences for your product, your team, and your cloud bill.
Traditional ML models return a constrained answer. A classification model tells you whether a transaction is fraudulent. A regression model gives you a number. You define the output space before training begins, and the model never steps outside that boundary.
Generative models work differently at a fundamental level. Instead of selecting from predefined categories, the model constructs output token by token from a learned probability distribution. The result, whether text, code, or images, did not exist before the model produced it. You cannot get that behavior from a classifier no matter how much you optimize it. The architectures solve categorically different problems.
ML models depend on labeled, structured datasets. Every training example needs a known outcome attached to it. Your annotation quality directly determines your model accuracy in production.
Generative AI flips that requirement entirely. Foundation models train on massive unstructured corpora, books, code repositories, web text, without manual labels. Most teams never train from scratch. They start with a pre-trained foundation model and adapt it through fine-tuning on domain-specific data or by building retrieval pipelines that inject curated context at inference time.
That shift means your data strategy moves away from labeling pipelines and toward curation, chunking, and retrieval quality.
Standard ML uses supervised learning. You feed the model labeled examples, it minimizes prediction error against known outputs, and training stops when accuracy meets your threshold.
Generative foundation models use self-supervised pretraining. The model predicts the next token in a sequence using the sequence itself as the label. No human annotation required. This is how GPT-style models absorb patterns across billions of text samples before you ever touch them.
Once you have a pre-trained foundation model, two adaptation paths open up. Fine-tuning updates the model weights on your domain-specific data, baking new behavior directly into the model. Retrieval-augmented generation, or RAG, takes a different approach: instead of retraining, it retrieves relevant context from an external knowledge base at query time and injects that context into the prompt. RAG systems rely on vector embeddings to represent documents as numerical coordinates in high-dimensional space, then use a retrieval system to pull the most semantically similar chunks for any given query. The model reasons over retrieved content rather than relying solely on what it memorized during pretraining. This approach keeps your knowledge base current without retraining costs.
| Dimension | Machine Learning | Generative AI |
|---|---|---|
| Output | Prediction, score, or label | Generated text, code, images, or audio |
| Data | Structured, labeled datasets | Unstructured corpora, often unlabeled |
| Training approach | Supervised, task-specific | Self-supervised pretraining plus fine-tuning or RAG |
| Common model types | Decision trees, gradient boosting, neural classifiers | Transformers, diffusion models, LLMs |
| Inference cost | Low to moderate | Moderate to very high |
| Latency | Milliseconds | Hundreds of milliseconds to several seconds |
| Explainability | High for tree-based models, moderate for neural | Low, outputs are probabilistic and context-dependent |
| Evaluation method | Accuracy, precision, recall, AUC | BLEU, ROUGE, human eval, LLM-as-judge |
| Failure modes | Drift, label leakage, distribution shift | Hallucination, prompt injection, output inconsistency |
| Governance risk | Moderate | High |
Traditional ML inference is fast and cheap. A gradient boosting classifier returns a prediction in under 10 milliseconds at minimal compute cost. Generative model inference, especially with large context windows, consumes orders of magnitude more GPU compute per request. That cost difference matters enormously at scale.
Tree-based ML models are inherently interpretable. You can trace exactly which features drove a prediction. That matters in regulated industries like financial services and healthcare where decisions require auditable justification.
Generative models offer almost none of that transparency. Outputs are probabilistic. Two identical prompts can return different answers. Evaluation is harder too: you cannot score generated text with a single accuracy metric the way you score a classifier. Teams rely on ROUGE and BLEU scores for summarization tasks, human evaluation panels for quality, and increasingly on LLM-as-judge frameworks where a separate model scores outputs.
The governance risk profile is also higher. Generative models hallucinate, sometimes confidently presenting false information as fact. They are vulnerable to prompt injection attacks where malicious input hijacks model behavior. Getting AI governance right for generative systems requires output monitoring, content filtering, and clear escalation paths that most standard ML deployments never need.
Predictive ML earns its place in production because the output is always a number, a label, or a score. The problem space is fixed before you write a single line of training code, which makes these systems fast to validate and relatively cheap to run at scale.
Fraud detection is the clearest example. Your input is a transaction record: amount, merchant category, device fingerprint, location, and time since the last transaction. The model returns a risk score between 0 and 1. A score above your threshold triggers a block or a step-up authentication challenge. The KPI that matters here is false positive rate, because flagging legitimate purchases destroys user trust faster than actual fraud does. No generative model belongs anywhere near this pipeline. You need a calibrated probability, not a paragraph explaining why the transaction looks suspicious. See how this works in a real product context in our fintech fraud detection case study.
Churn prediction follows the same pattern. Input: 90 days of behavioral signals including login frequency, feature adoption depth, and support ticket volume. Output: a churn probability score per account. The KPI is lift over your baseline retention rate when you act on the top-decile predictions. A language model cannot reliably produce a calibrated probability score from structured behavioral data. A gradient-boosted classifier can.
Recommendation engines take user interaction history as input and return a ranked list of items. The KPI is click-through rate or downstream conversion. Collaborative filtering and matrix factorization have solved this problem well for years. Explore how recommendation logic works in practice in our recommendation system guide.
Demand forecasting feeds structured time-series data, promotions calendar, and seasonal indicators into a model that outputs inventory requirements or staffing levels for a future window. The KPI is forecast error rate, typically measured as MAPE.
All four of these machine learning use cases share one trait: the answer exists somewhere in historical data, and the model's job is to find the pattern that predicts it reliably.
Generative AI belongs in your stack when the output itself has to be constructed, not retrieved or scored. The tasks below involve turning structured inputs into coherent, contextually appropriate text or code, and each one comes with a specific implementation decision and a clear point where a human still needs to be in the loop.
Support ticket drafting is one of the highest-ROI applications available to B2B SaaS teams right now. The input is a CRM record: customer tier, product area affected, error logs, and the customer's raw message. GPT-4o or Claude 3.5 Sonnet works well here because both handle multi-field context without collapsing relevant detail. You pass the structured data as a system prompt template, let the model draft a response, and route that draft to an agent for a quick review before it goes out. Human review is mandatory on any ticket touching billing disputes or SLA compensation. Skipping that step has a measurable cost.
Contract summarization takes a 40-page MSA or vendor agreement as input and asks the model to extract key obligations, liability caps, termination clauses, and renewal dates into a structured output. A RAG pipeline with a document chunking strategy works better than feeding the full document in a single context window, especially for contracts over 20,000 tokens. Human review is required before any summary gets used in a negotiation or compliance workflow. Models hallucinate specific dollar amounts and dates often enough that you cannot treat the output as ground truth without verification. For implementation guidance, our document drafting and summarization guide covers the technical setup.
Code completion uses the developer's current file, surrounding context, and cursor position as input. GitHub Copilot runs on OpenAI Codex, but teams building internal tools often fine-tune a smaller model like DeepSeek Coder on their proprietary codebase to keep suggestions consistent with internal conventions. Human review happens at the pull request stage, not line by line.
Multilingual content localization takes a source-language marketing asset or product string as input and produces translated, culturally adapted copy. GPT-4o handles 30-plus languages at production quality for most European and Asian markets. The implementation approach typically involves a two-pass process: model translation followed by a native-speaker review for brand voice accuracy. Human review is non-negotiable for regulated markets where mistranslation carries legal exposure.
For teams building customer-facing conversational interfaces on top of these capabilities, our customer-facing chat assistants guide walks through the architecture decisions that matter most in production.
Most product teams lose time not because they built the wrong thing, but because they picked the wrong tool before they fully understood the problem. The machine learning vs generative AI decision has real downstream consequences for your data pipeline, your cloud bill, your team structure, and how fast you can ship.
Run through these questions before committing to either path:
Choose ML if your problem has a fixed output space, labeled training data, strict latency requirements, or a compliance environment that demands full decision traceability.
Choose generative AI if your users expect the system to handle open-ended inputs, produce novel content, or interact conversationally across topics you cannot enumerate in advance.
Use both if your product needs prediction models to handle scoring or ranking and a generative layer to explain, summarize, or surface those results to end users.
The most practical architecture for generative AI vs machine learning isn't a binary choice. It's a layered system where ML handles the heavy quantitative lifting and generative AI handles communication.
Here's a realistic example from a B2B SaaS lending platform. The ML layer runs a gradient boosting model that scores loan applications for default risk in real time. That model processes structured inputs, outputs a probability score, and logs every decision for compliance review. Fast, auditable, deterministic.
The generative AI layer sits downstream. When an underwriter opens a flagged application, the system sends the ML score, the top contributing features, and relevant applicant history to a large language model. The LLM generates a plain-English explanation of why the application was flagged, what factors drove the score, and what additional documentation might resolve the risk concerns.
The ML model makes the call. The generative model explains it.
This pattern applies across domains. An e-commerce platform might use ML for product ranking and generative AI to write personalized recommendation copy. A fraud detection system might use ML to score transactions and generative AI to produce analyst-facing summaries of suspicious account behavior.
If your hybrid architecture includes retrieval-augmented generation, your data strategy gets more complex. RAG means your generative layer is pulling live context from a vector database at inference time rather than relying solely on what the model learned during training. That changes your ML project delivery for data engineering teams significantly: you now own a retrieval pipeline, an embedding refresh schedule, and a new class of observability problem.
Standard ML monitoring tracks prediction drift and data distribution shifts. RAG adds retrieval quality to that list. You need to track whether the right documents are being surfaced, whether the context window is being saturated with noise, and whether your embeddings have gone stale since your last ingestion run. Teams that skip this monitoring layer ship systems that quietly degrade as their knowledge base grows.
Build the observability stack before you go to production, not after the first incident.
The generative ai vs machine learning decision is ultimately a function of five variables: what output your product needs to produce, how much quality data you actually have, what your cloud budget can absorb, how much risk you can tolerate in production, and what kind of experience your users expect. None of those variables live in isolation.
Three rules worth keeping:
If you're still working through which path fits your specific use case, the Brilworks team can help. From architecture selection and model evaluation to AWS implementation and production deployment, we've done this across enough product categories to skip the costly trial-and-error phase. Talk to us about your AI build and we'll get specific fast.
The key difference in Generative AI vs Machine Learning is that Machine Learning is a broad field encompassing algorithms that learn from data to make predictions or decisions, while Generative AI is a specific subset of Machine Learning focused on creating new, original content. In the Generative AI vs Machine Learning comparison, traditional Machine Learning analyzes and classifies existing data, whereas Generative AI generates entirely new text, images, code, audio, or video based on learned patterns.
Yes, when comparing Generative AI vs Machine Learning, Generative AI is actually a specialized branch within Machine Learning. Machine Learning is the umbrella term that includes supervised learning, unsupervised learning, reinforcement learning, and deep learning, with Generative AI falling under deep learning. Understanding Generative AI vs Machine Learning means recognizing that Generative AI uses advanced Machine Learning techniques like neural networks and transformers to create new content.
Use cases differ significantly in Generative AI vs Machine Learning applications. Traditional Machine Learning excels at prediction (fraud detection, recommendation systems), classification (spam filtering, medical diagnosis), and optimization (supply chain, pricing). Generative AI vs Machine Learning use cases show Generative AI shines in content creation (writing, image generation), code development, virtual assistants, design automation, and creative applications. The Generative AI vs Machine Learning decision depends on whether you need to analyze/predict or create/generate.
The choice in Generative AI vs Machine Learning depends on your business needs. Choose traditional Machine Learning when you need to analyze data, make predictions, detect patterns, or automate decision-making based on historical data. Select Generative AI when you need to create content, automate creative tasks, generate personalized experiences, or build conversational interfaces. Most businesses benefit from both in the Generative AI vs Machine Learning decision, using each for appropriate use cases.
Technical differences in Generative AI vs Machine Learning include model architecture, training approaches, and outputs. Traditional Machine Learning uses algorithms like decision trees, random forests, and support vector machines with structured data, while Generative AI employs complex neural networks like transformers, GANs, and diffusion models trained on massive unstructured datasets. In Generative AI vs Machine Learning comparisons, Generative AI requires significantly more computational resources, larger training datasets, and produces creative outputs rather than predictions or classifications.
You might also like
Hello, we are BRILLIAN’S. Trying to make an effort to put the right people for you to get the best results. Just insight !
